【LINEbot】天気予報くんをつくる(その2 地域IDを取得)
前回のつづき rkdora.hatenablog.com
前回で、久留米市の天気予報を取得することができた。
その他の地域の天気予報を取得したい。
そのためには、全国の地域IDを取得する必要がある。(久留米は[400040])
ここでは、全国の地域IDをスクレイピングで取得し外部ファイルに辞書として保存することにする。
スクレイピングする準備
pipenv install bs4 pipenv install lxml
scrape.py
import requests as rq from bs4 import BeautifulSoup as bs4 import pickle url = 'http://weather.livedoor.com/forecast/rss/primary_area.xml' path = 'city_dict.pickle' res = rq.get(url) soup = bs4(res.content, 'xml') city_tags = soup.find_all('city') city_dict = {} for city in city_tags: city_dict[city['title']] = city['id'] print(city_dict) with open(path, mode='wb') as f: pickle.dump(city_dict,f)
city_dict.pickleに入れたもの
{'稚内': '011000', '旭川': '012010', '留萌': '012020', '網走': '013010', '北見': '013020', '紋別': '013030', '根室': '014010', '釧路': '014020', '帯広': '014030', '室蘭': '015010', '浦河': '015020', '札幌': '016010', '岩見沢': '016020', '倶知安': '016030', '函館': '017010', '江差': '017020', '青森': '020010', 'むつ': '020020', '八戸': '020030', '盛岡': '030010', '宮古': '030020', '大船渡': '030030', '仙台': '040010', '白石': '040020', '秋田': '050010', '横手': '050020', '山形': '060010', '米沢': '060020', '酒田': '060030', '新庄': '060040', '福島': '070010', '小名浜': '070020', '若松': '070030', '水戸': '080010', '土浦': '080020', '宇都宮': '090010', '大田原': '090020', '前橋': '100010', 'みなかみ': '100020', 'さいたま': '110010', '熊谷': '110020', '秩父': '110030', '千葉': '120010', '銚子': '120020', '館山': '120030', '東京': '130010', '大島': '130020', '八丈島': '130030', '父島': '130040', '横浜': '140010', '小田原': '140020', '新潟': '150010', '長岡': '150020', '高田': '150030', '相川': '150040', '富山': '160010', '伏木': '160020', '金沢': '170010', '輪島': '170020', '福井': '180010', '敦賀': '180020', '甲府': '190010', '河口湖': '190020', '長野': '200010', '松本': '200020', '飯田': '200030', '岐阜': '210010', '高山': '210020', '静岡': '220010', '網代': '220020', '三島': '220030', '浜松': '220040', '名古屋': '230010', '豊橋': '230020', '津': '240010', '尾鷲': '240020', '大津': '250010', '彦根': '250020', '京都': '260010', '舞鶴': '260020', '大阪': '270000', '神戸': '280010', '豊岡': '280020', '奈良': '290010', '風屋': '290020', '和歌山': '300010', '潮岬': '300020', '鳥取': '310010', '米子': '310020', '松江': '320010', '浜田': '320020', '西郷': '320030', '岡山': '330010', '津山': '330020', '広島': '340010', '庄原': '340020', '下関': '350010', '山口': '350020', '柳井': '350030', '萩': '350040', '徳島': '360010', '日和佐': '360020', '高松': '370000', '松山': '380010', '新居浜': '380020', '宇和島': '380030', '高知': '390010', '室戸岬': '390020', '清水': '390030', '福岡': '400010', '八幡': '400020', '飯塚': '400030', '久留米': '400040', '佐賀': '410010', '伊万里': '410020', '長崎': '420010', '佐世保': '420020', '厳原': '420030', '福江': '420040', '熊本': '430010', '阿蘇乙姫': '430020', '牛深': '430030', '人吉': '430040', '大分': '440010', '中津': '440020', '日田': '440030', '佐伯': '440040', '宮崎': '450010', '延岡': '450020', '都城': '450030', '高千穂': '450040', '鹿児島': '460010', '鹿屋': '460020', '種子島': '460030', '名瀬': '460040', '那覇': '471010', '名護': '471020', '久米島': '471030', '南大東': '472000', '宮古島': '473000', '石垣島': '474010', '与那国島': '474020'}
main.py
from flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage ) import os import requests as rq import json import pickle app = Flask(__name__) LINE_CHANNEL_ACCESS_TOKEN = os.environ["LINE_CHANNEL_ACCESS_TOKEN"] LINE_CHANNEL_SECRET = os.environ["LINE_CHANNEL_SECRET"] line_bot_api = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(LINE_CHANNEL_SECRET) city_path = 'city_dict.pickle' def get_weather_info(city_num): url = 'http://weather.livedoor.com/forecast/webservice/json/v1?' city_params = {'city': city_num} data = rq.get(url, params=city_params) content = json.loads(data.text) content_title = format(content['title']) content_text = format(content['description']['text']) content_time = format(content['description']['publicTime'])\ .replace('T', ' ').replace('-', '/')[:-5] return content_title + '\n\n' + content_text + '\n\n最終更新日時:' + content_time @app.route("/callback", methods=['POST']) def callback(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) app.logger.info("Request body: " + body) try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): user_message = event.message.text with open(city_path, mode='rb') as f: city_dict = pickle.load(f) if user_message in city_dict: message = get_weather_info(city_dict[user_message]) else: message = '対応していません。' line_bot_api.reply_message( event.reply_token, TextSendMessage(text=message)) if __name__ == "__main__": port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)


つづく
【LINEbot】天気予報くんをつくる(その1 天気予報を取得)
目的
Pythonを用いたLINEbot開発を通して、スクレイピング・データベースまわりを理解する
開発するもの
天気予報くん
各地域の天気予報を教えてくれるLINEbot
開発環境
- Ubuntu 18.04
- Python 3.6.9
- Pipenv
- Flask 1.1.1
- Line-bot-sdk 1.16.0
- Heroku
- PostgreSQL
APIを叩く
お天気Webサービス
お天気Webサービス(Livedoor Weather Web Service / LWWS)は、現在全国142カ所の今日・明日・あさっての天気予報・予想気温と都道府県の天気概況情報を提供しています。
※すでにサービス終了しています(2021年3月追記)
ファイル構成
. ├── main.py ├── Pipfile ├── Pipfile.lock ├── Procfile └── weather.py
main.py
from flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage ) import os import weather as wt app = Flask(__name__) LINE_CHANNEL_ACCESS_TOKEN = os.environ["LINE_CHANNEL_ACCESS_TOKEN"] LINE_CHANNEL_SECRET = os.environ["LINE_CHANNEL_SECRET"] line_bot_api = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(LINE_CHANNEL_SECRET) @app.route("/callback", methods=['POST']) def callback(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) app.logger.info("Request body: " + body) try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): # message = event.message.text city_num = '400040' message = wt.get_weather_info(city_num) line_bot_api.reply_message( event.reply_token, TextSendMessage(text=message)) if __name__ == "__main__": port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)
weather.py
import requests as rq import json def get_weather_info(city_num): url = 'http://weather.livedoor.com/forecast/webservice/json/v1?' city_params = {'city': city_num} data = rq.get(url, params=city_params) content = json.loads(data.text) content_title = format(content['title']) content_text = format(content['description']['text']) content_time = format(content['description']['publicTime'])\ .replace('T', ' ').replace('-', '/')[:-5] return content_title + '\n\n' + content_text + '\n\n最終更新日時:' + content_time
動作
ユーザーからのメッセージに反応し、福岡県久留米市の天気概況を返す。
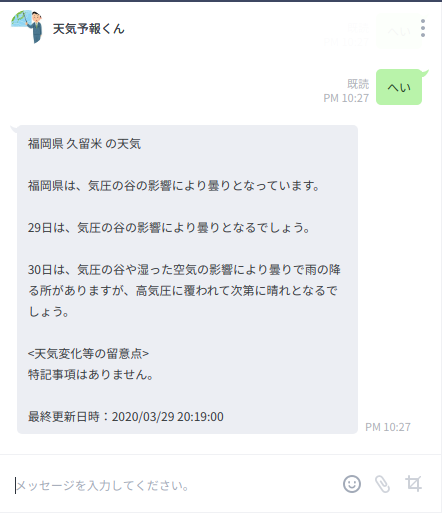
つづく
物体検出(YOLOv3)による洗濯表示の検出
Wash Mark Checker
以前書いた、洗濯表示しらべくんのその後。
洗濯表示しらべくんから名前を変え、 Wash Mark Checkerとして開発を再スタートした。
英語名にしたのは、洗濯表示が世界共通のものであることから世界中で使えるものにしたいと考えたため。
相棒のたなっちとともに開発を行った。
洗濯表示しらべくんは、洗濯表示を一つずつしか調べることが出来なかった。

トリミングがとても面倒で、洗濯表示一覧から探すほうが正直楽だった。
Wash Mark Checkerでは、洋服タグ内の洗濯表示をまとめて調べることができるようにした。

以下、プレゼンとスライド。
開発期間
2019/09/20 ~ 12/21
12/21がチャレキャラ2019の発表会だった。
前半はほとんど手を付けておらず、実際に開発していた期間は2~3週間くらい。
開発の流れ
1. 洋服タグの画像を集める
200枚程度用意した。
2. アノテーション
集めた洋服タグの画像内に含まれる洗濯表示一つ一つに対して、手作業でアノテーションを行う(範囲選択・分類)。
めちゃくちゃしんどかった。
つまずいた点
はじめは、すべての洗濯表示に対して同じクラスに分類させようとしていた。
思い描いてた流れとしては、
- 洋服タグから洗濯表示の部分をトリミングする。
- CNNを用いて、41種類に分類する
しかし、うまくいかなかった。
はじめから41種類のクラスに分類させるようにしたところうまくいった。
3. YOLOv3で学習を行い、重みを保存
CPUで学習を行ったため、かなり時間がかかった(4日間程度)。
研究室で余っていたPCに働いてもらった。
参考記事:
【物体検出】keras−yolo3の学習方法 | エンジニアの眠れない夜
つまずいた点
GPUでやりたく、Google Colaboratoryで学習を試みた。しかし、そのままのコードでは動かなかった。 Google Colaboratory上で動かすために、コードを改変させることが必要だったと思われるがよくわからなかった。
4. FlaskでWEBアプリ化
ブラウザからアップロードした画像に対して、洗濯表示の検出ができるようにした。
つまずいた点
iOSからアップロードされる画像が90°回転してしまう問題に直面した。
調べてみると、Exifという画像に含まれる情報によるものだった。
Exif対策を行うことで、対処できた。
参考記事:
【Python】EXIF情報に合わせて画像を回転させる|MAX999blog
5. レンタルサーバーにデプロイ
ロリポップ!マネージクラウドにデプロイした。(2020年3月現在、非公開)
つまずいた点
大きなファイルをデプロイするとき。重みファイルが200MB以上あったため、Google Driveにアップロードしたものをwgetによってダウンロードするようにした。
つまずいた点
初回起動時、tensorflowの起動に時間がとられタイムアウトしてしまう。
起動時のコマンドに-t 300とすることで、タイムアウトまでの時間を300sまで伸ばすことができるようになった。
問題点
20分で終了してしまうため(レンタルサーバーの仕様)、しょっちゅう初回起動になり起動までの時間を待たなくてはいけなくなる。
精度
8割程度の正答率。
マイナーな洗濯表示になればなるほど、正答率が下がるイメージ。
マイナーな洗濯表示を学習させるために、一覧の画像を学習させてみたりした。
感想
洗濯表示しらべくんで満足せずに、洋服タグから複数の洗濯表示を一気に識別することにこだわり続けることが出来てよかった。 イベントなどで多くの人に「欲しい!」と言ってもらえたときがめちゃくちゃうれしかった。
目の前の卒論から逃げるように開発をしていたが、終わってしまったので卒論に集中しなければ。。。(執筆時12月末)
【JPHACKS2019】Award Dayを振り返って
JPHACKS2019のAward Dayに、プロ研メンバー4名でチーム「もつなべ」として参加してきました。 この記事は、その際の参加レポートです。
JPHACKS2019 Award Day参加レポート
JPHACKSとは
JPHACKS(ジャパンハックス)は、学生を対象にした日本最大規模のハックイベントで、2014年より全国の複数都市で開催されています。 2日間で開催される「Hack Day(ハックデイ)」でチーム開発をおこない、そこから選ばれたファイナリスト達が、東京に集い ピッチや展示会をおこなう「Award Day(アワードデイ)」で構成されています。jphacks.com
Award Dayとは
Hack Dayにて提出されたプロダクトの中から、審査委員会にてオンライン審査を実施し、合計15チームのAward Day進出チームを決定致します。選出されたチームは、東京で開催されるAward Dayにて、プロダクトの発表、展示会による出展をおこない、JPHACKS Innovator認定を得られる権利が与えられます。開催概要 - JPHACKS2019 参加者向けガイドライン

時系列で振り返る
Hack Dayに関しては前記事で詳しく振り返っています。
Hack Day後からAward Day直前まで
Award Day進出決定
Hack Dayが10月19と20日。その日からおよそ2週間後の11月1日にAward Day進出チームが発表されました。
私たちのチームはHack DayにてBest Hack Day Awardを頂いていましたが、Award Day進出には関係なかったので発表当日までドキドキしっぱなしでした。
発表は12時ちょうどにHP上にて公開する形で行われました。
研究室のPCからアクセスし、
ドキドキしながら下へ、下へ、
東京チーム、
東京チーム、
東京チーム、、、
東京多くね!?!?(なんと15チーム中7チームが東京会場から選出)
下へ、
さらに下へ、、
うおおおおおおおおおおおお!!!!!!(リアルに大声)

「JPHACKS 2019 Award Day」進出チーム 15組を発表 | JPHACKS
速攻でメンバーに共有

ひとしきり騒いだあとに、ほかのチームと動画を見比べてみて、、、
おれらのチームの動画、プロダクトがなにか全然伝わんない(笑)
他のチーム、レベル高いなーなんて思いながら見ていると
あ、釘君チームいる!!(去年enPiTで知り合った広大の友達のチーム)
と、またまたテンションが上がり。
そんなこんなでAward Dayに進出することが決まりました。
さあ、プロダクトをパワーアップさせるぞ!(Award Dayは11月9日。一週間しかない。。。)
プロダクトの改善
ということでAward Dayまでに実装できた、Hack Dayからの主な改善点は以下の三点。
一点目 プレゼン動画解析時の進行状況を表示
動画の解析には時間がかかります。
Hack Dayの時点では、解析時にあとどれくらいで終わるか裏画面(ターミナル)を見ないとわかりませんでした。
そこで、解析状況をデータベースを経由してAjaxによって画面に表示させることで解析の進行状況が分かるようになりました。

二点目 結果表示画面のUIをより分かりやすく
視線の高さや、全体を見渡せているかを数値だけでなくイラストで直感的に把握できるように。 その他にも、スコアを大きくしたり、配置を整えたり。

三点目 スコア算出時に機械学習を用いる
Hack Day時点では、人間がきめたパラメータによってスコアを算出していました。 プレゼンデータを追加でさらに用意し、それぞれのプレゼンの点数と特徴から機械学習によって最適なスコアを算出できるようになりました。
詳しくは、メンバーの記事にて(公開され次第、追記します)。
これらの改善のほとんどが東京で完成しました(前乗りで東京にいたので、徹夜での開発)。
本当にメンバーには感謝でいっぱいです。

東京に行く際はぜひ。
Award Day当日
8時30分集合。 会場は東京大学の講堂。

いざ、入らん。
ガチャ。
ガチャガチャガチャ。
あれ、鍵が閉まってる。
反対側かな?
テクテクてくてく。
入れない。。。
情報を確認。
弥生講堂!?!?!?
講堂が他にもあるんかい。
しかもまあまあ遠い。
遅刻しました。ごめんなさい。
プレゼン
プレゼンテーションがテーマのプロダクトのプレゼン、めちゃくちゃハードル高いよおおおおおおお。
緊張はしましたが、やりきれてよかったです。
他のチームのプレゼンでは、ひたすら圧倒されっぱなしでした。 さすが全国。レベルが高い。
当日の様子は、ツイッターで「#jphack2019」で検索するとなんとなく伝わると思います。
デモ
プレゼンの後は、各チーム決められたブースでデモ展示です。
ポスターを用意しているチームが多かったです。
そこまで余裕はなかったのでスライドで代用。

多くの方とお話させていただきました。
特に印象的だったのが、一人の審査員の方がiPadを持ってきて
「TEDでどうなるか試してみてよ!」と
「おもしろいですね!やりましょう!」とは言ったものの、ドキドキしながら動画をアップロードし、、、

みんなで「うおおおおおおおおおお」と驚きました(笑)
いろんな方にプロダクトをほめていただき最高にうれしいひとときでした。
表彰
富士フイルム賞とイノベーター認定を頂きました!
JPHACKS2019 Award Dayにて、「もつなべ」がイノベーター認定と富士フィルム賞を頂きました!
— 九工大プロ研 (@kyutech_proken) November 9, 2019
最高の1日でした!
関係者の皆様、本当にありがとうございました!
#もつなべ #プレゼンテーションチェッカー#JPHACKS2019 #jphacks #プロ研216 pic.twitter.com/oSUqQon0Cj
富士フイルムさんからは、景品として一人一台ずつチェキを頂きました。
めちゃくちゃうれしかったです。 ありがとうございました。
懇親会

釘くんチームの二人をはじめとする参加者、企業の方、審査員の方々など多くの方とお話させていただきました。
あっというまに時間が過ぎました。
まとめ
JPHACKSのAward Day、まじで最高でした。
どのプロダクトもレベルが高く、尊敬している人が審査員として参加していたり、賞も豪華だったり、、、
本当に参加できてよかったです。
プロダクトは、JPHACKS用にNECさんから提供いただいた遠隔視線推定APIを使用していることもあり一区切りとなります。
また機会があったら違うアプローチでプレゼンテーションチェッカーをパワーアップさせていきたいと思います。
学生最後にこんな経験ができたのも、いい仲間と出会えたからだと思ってます。 メンバー、参加者のみなさん、審査員や運営の方々、ありがとうございました!
釘君も参加レポートを書いているので、ぜひ!
【JPHACKS2019】プレゼンチェッカー
JPHACKS2019のHackDay福岡に、プロ研のメンバー4名でチーム「もつなべ」として参加してきました。 この記事は、その際の参加レポートです。
JPHACKS2019 HackDay福岡参加レポート
JPHACKSとは
JPHACKS(ジャパンハックス)は、学生を対象にした日本最大規模のハックイベントで、2014年より全国の複数都市で開催されています。 2日間で開催される「Hack Day(ハックデイ)」でチーム開発をおこない、そこから選ばれたファイナリスト達が、東京に集い ピッチや展示会をおこなう「Award Day(アワードデイ)」で構成されています。jphacks.com
Hack Day 福岡

実際には10チームだったと思います。
他のハッカソンで賞をもらっている顔ぶれが多く、レベルの高さにビビりまくってました。
結果
な、な、なんと、Best Hack Day Awardを頂きました!


マジで驚きました。
予想外すぎて、コメントを求められた際に「目がいっぱいある〜(泣)」としか言えずに大変恥ずかしい思いをしました。
改めて、この場で。
投票していただいたみなさま、本当にありがとうございました。
発表
プレゼン
デモ動画
プレゼンチェッカー
テーマ
プレゼンテーション x Tech
ターゲット
プレゼンテーションスキルを向上させたい人
解決したい課題
プレゼンテーションの練習をする際などに、視線や声の抑揚を客観視できるものが欲しい
特長
- プレゼンテーションのスキルを数値化できる
視線や声の抑揚に基づいてスコアを算出 - 視線推定技術(NEC遠隔視線推定API)を用いて、プレゼンターの視線を解析
左右 => 左右に視線に偏りがないか
上下 => 下を向いていないか
分布 => 全体を見渡せているか - フーリエ変換を用いて、プレゼンターの声の抑揚を解析
声の大きさの分布
声のトーンの分布
使用方法
- プレゼンテーションを撮影
- 動画をアップロード
- 視線、声の抑揚に基づいてスコアを表示(視線データが合成された動画のダウンロードも可能)
開発内容・開発技術
API
フレームワーク
- Flask
独自の工夫
- フーリエ変換を用いた声の抑揚の抽出
- 視線データと抑揚のデータからプレゼンテーションスキルを数値化
- 視線を残像のようにデータ表示した動画の生成
開発を振り返って
アイデア出し
2019年のテーマは「X-Tech 2019 ~Innovation for myself & by my hacks ~」とし,自身(一人称)の問題を自身(一人称)で解決することを目指してほしいと考えています.
テーマは10日前に発表されました。
今回のテーマからSNS系以外で考えることにしました。
メンバー間でアイデア出しを行いましたが、なかなかいいアイデアが浮かびませんでした。
JPHACKS用に提供されている技術を眺めていたところ、NEC様からの「遠隔視線推定技術」がおもしろそうだということになりました。
結局、Hack Day当日までに具体的なアイデアが出ませんでした。
Hack Day当日になり、開発時間がスタート。
遠隔視線技術が特別にAPIとして提供されていたので、まずは動作確認を行い実際に動くことを確認しました。
その後、出たアイデア達です↓
プレゼンテーション時の、プレゼンターの視線が聴衆に向いているかを数値化する
プレゼンテーション時の、聴衆の視線がスライドのどこを見ているかを特定する
視線外しゲーム(画面内の美少女と視線が合ったら負け)
画像いらすとや変換器(画像内の人間をいらすとやのイラストに置き換える)
15時くらいにやっと、 プレゼンターの視線が聴衆に向いているか・声に抑揚があるかを数値化するというアイデアに固まりました。
開発手法
MVP(実用最小限の製品: minimum viable product)
- 動画をアップロードできるWEBアプリの実装
- 動画からプレゼンターの視線の平均・分散を算出し、結果として表示
1up
2up
- 視線・声のデータからスコアを算出して表示(パラメータ調整)
- 音声の波形表示(間に合わず)
その他
APIを叩く際に、うまくいく時といかない時がありかなり苦労しました。 回線や画像サイズの問題と思われます。
難しいところは全部、たなっち(tanacchi (@q111026d) | Twitter)という頼れる相棒が実装してくれました(尊敬)。
動画アップロードやローディング画面など、WEBアプリとしての機能は後輩の2人が頑張ってくれました(感謝)。
もちろん、今回も夜通しでの開発。
初めてAirbnbを使いました。
実際に泊まったところ↓
現地の人から借りる家、体験&スポット - Airbnb
個室で、Wifiもあって、シャワーもトイレもあって、過去イチの夜間開発環境でした。 朝、駅に着いた時に上着を部屋に忘れていたことに気づいて取りに帰るなんてことも・・・(1時間ほど遅刻)
スポンサーさまからの差し入れで飲み物・お菓子があり、会場の開発環境もとてもよかったです。
良いプレゼン、悪いプレゼンのサンプルを撮るだけで合計2時間ほど費やしました。
その大半が、良いプレゼンに挑戦する時間。そのうちNG集作ります。
良いプレゼンってほんと難しい( ;∀;)
発表を振り返って
- 90秒という短い時間
- プロダクトがプレゼンに関するもの
といったプレッシャーがある中で、最低限伝えたいことは伝えることができたかな〜と感じています。
視線と声の抑揚に関しては、もっと意識しときたかったな〜というのが反省点(o_o)
今後
プレゼンスコアを算出するパラメータを機械学習によって設定できるようになれば、より良いものになると思います。
また、企業さんからのフィードバックにもあった「え〜」「あの〜」などのフィラー検出も挑戦したいです。
画像認識による洗濯表示の識別
洗濯表示しらべくん
画像から洗濯表示を識別し、意味を表示するWEBアプリケーション。
CNNによりモデルを作成し、FlaskでWEBアプリ化、Herokuにデプロイしてある。
TOP画面

予測結果表示画面

洗濯表示とは?
衣服についたタグのマークのこと。 洗濯や乾燥の方法、アイロンのかけ方やクリーニングの方法などが示されている。 全41種類。世界共通。

デモ動画
HAIT Lab 福岡にて、Best Product Awardを受賞。
GitHub - HAIT-Lab-Fukuoka-TeamC/care-label-app: 洗濯表示しらべくん
開発期間
2019/09/09 ~ 09/16
開発の流れ
- 洗濯表示41種類、約200枚を集める
- 約30万枚(30GB弱)に水増し (明るさ、ノイズ、回転、移動)
- CNNを用いてモデルを作成し、重みを保存
- FlaskでWebアプリ化
- Herokuにデプロイ
1. 洗濯表示41種類、約200枚を集める
洗濯タグを撮影→トリミング→該当するフォルダに仕分け。
珍しい洗濯表示などは、ネットから集めた。
https://github.com/HAIT-Lab-Fukuoka-TeamC/care-label-app/tree/master/pre-all/train-seeds
2. 約30万枚(30GB弱)に水増し
1枚の画像から1500枚弱に水増しする。
DeepLearningには大量のデータが必要と聞いていたため、大量に用意することにした。
明るさ、ノイズ、回転、移動(縦横斜め)それぞれを段階的に複合させることで水増しを行う。
水増しにはOpenCVを用いている。
工夫した点
1回のプログラム実行で全ての種画像を水増しできること。
それまでは、1回のプログラム実行で1枚から1500枚に水増しを行なっていた。ただ、これでは200枚の種画像を水増ししようとすると200回プログラムを書き直して実行しなければならない。
そこで、globモジュールを使いファイル・フォルダ名を取得することにより1回のプログラム実行で200枚の種画像をそれぞれ1500枚、計30万枚へと水増しできるようになり、作業効率が大幅に改善した。
つまずいた点
Linux(ノート)とWindows(デスクトップ)で開発を往復することがあり、Windowsでうまく動作しなかった。
Windowsで使う際にはパスを「/」から「¥¥」へと変える必要があることがわかった。
3. CNNを用いてモデルを作成し、重みを保存
画像サイズを50×50に。


CNNの層の決め方はよくわからなかった。
# CNNを構築 model = Sequential() model.add(Conv2D(32, (3, 3), padding='same',input_shape=X_train.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(len(folder))) model.add(Activation('softmax'))
epoch数は3で訓練し、評価は
[0.011538714563043074, 0.9979025710419486]
trainデータ、testデータ共に99%ほどの精度に。
ただ、この数字は全く参考にならない。
種画像を水増ししたもので評価しているためだ。
体感では、8割程度の精度だと感じている(種画像の数や、似ているものがあるかどうかで結構ばらつく)

つまずいた点
30万枚という大量のデータを学習させようとすると、長時間かかるためjupyter-notebookでは辛いものがあった。(セッション切れなど)
Google ColaboratoryによりGPUを使うことも試してみたが、そのためにはデータをGoogleドライブにおく必要があった。
30万枚をアップしようとしたものの、長時間かかりエラーを吐かれ断念。
Google Colaboratory上で画像を水増しし、Google Driveに直接出力しようとしたものの、時間がかかりすぎるため断念。
結局、Jupyter NotebookのコードをそのままPythonファイルにしてデスクトップで実行することで解決。1時間程度で学習が終わった。
4. FlaskでWebアプリ化
3で保存したモデルと重みを用い、アップロードされた画像に対して洗濯表示を予測する処理を裏で行う。
Top画面と、結果出力画面の2画面構成。
工夫した点
Top画面には使い方を載せた。
つまずいた点
Flaskにおける画像の表示
解決策は2つ。
- ルーティング処理(自分はこちらを選択。uploadsフォルダを作り、ルーティング処理をした。app.pyの下の方)
または - staticフォルダ下に画像を配置する
Djangoと比べてとても楽に感じた。
小さい規模のアプリケーションならFlaskの方がお手軽だと思う。
5. Herokuにデプロイ
軽量化させるため、heroku用にリポジトリを分けた。
ソースコードは以下の通り。
GitHub - HAIT-Lab-Fukuoka-TeamC/care-label-heroku
構成は以下の通り。

and_weight.hdf5、and.jsonは意味なし。
つまずいた点
Herokuにデプロイできない。
requirements.txtでエラーがでた。調べたところ、pyenvによる仮想環境の構築を行なっていなかったことが原因だった。(Anacondaもrequirementsに含まれている状態がいけなかったらしい)
pyenvにより仮想環境の構築をすることで解決。
つまずいた点
Herokuにアップロードした画像を保存できない。
元々は、「画像をアップロード→uploadsフォルダに保存→予測結果表示画面に保存した画像を表示」という構成だった。
ローカルでは、上の構成でうまく動作していたのだがおそらくHerokuの仕様により保存できなかった。
そこで、保存しない構成に変更した。具体的には、画面遷移時にデータを渡す構成にした。
感想
機械学習を用いた初めてのプロダクトになった。Pythonや機械学習、OpenCVによる画像処理、FlaskによるWEBアプリ化などわからないことだらけだったが、短期間でなんとか形にすることができてよかった。
画像認識による洗濯表示の識別は、自分が調べた中では過去に例がなかったので思いつくことができてよかった。
今は撮った画像をトリミングしてからアップロードする必要があるが、ゆくゆくは撮った画像をそのままアップロードし、複数の洗濯表示を識別するところまで持っていきたい。
参考記事
KerasのCNNを使用してオリジナル画像で画像認識を行ってみる - AI人工知能テクノロジー
Re:ゼロからFlaskで始めるHeroku生活 〜環境構築とこんにちは世界〜 - Qiita
【Hack U 2019 FUKUOKA】エナしるべ
Hack U 2019 FUKUOKAに参加しました。
SPAJAMの時と同じメンバーで参加し、チーム名は「もつなべ」としました。
Hack U 2019 FUKUOKA参加レポート
Hack U 2019 FUKUOKAとは
ヤフー主催学生ハッカソン。福岡会場では、以下のスケジュールで行われた。
- 開発期間 2019年08月05日(月)~08月23日(金)
- 発表・表彰 2019年08月24日(土)
参加チームは25チーム、総参加者は100名を超えた。
Hack U 2019 FUKUOKA Student Hackathon - Yahoo! JAPAN
発表
発表の様子は、下のリンクから見れるのでぜひ。
プレゼン 20:20~
デモ 2:11:55~
スライド
スライド内の動画は、リンク先から確認できます。
エナしるべ

概要
現在地周辺のエナジードリンク(以下、魔剤)を売っている場所をMAP上に表示する
機能
魔剤スポット
- 表示(MAP上、詳細)
- 追加
- 編集
魔剤フィルター
魔剤
- 追加
- 削除
技術
- monaca
- ニフクラ mobile backend
- Google Maps API
開発を振り返って
アイデア出し
とても苦労しました。
ただ、メンバーの一人が「魔剤」というパワーワードを口にしてからは一気にアイデアを深めることができました。
この時点で発表まで残り一週間( ;∀;)
開発手法
今回の開発では、レベルをMVP、1up、2up、3upの4段階に分けました。
MVP(実用最小限の製品: minimum viable product)
位置情報を投稿 投稿された位置情報を基にMAP上にピンを表示
→ どこで魔剤を売っているかが分かる
1up
位置情報+テキスト+魔剤の種類を投稿
魔剤フィルタ
→ どこでどんな魔剤が売っているかが分かる
2up
位置情報+テキスト+魔剤の種類+画像を投稿
→ どこでどんな魔剤を売っているかが詳細に分かる
3up
位置情報+テキスト+画像を投稿
画像認識により、魔剤の種類を特定&情報追加
→ どこでどんな魔剤を売っているかが詳細に分かる
→ 効率化
最終的には2upまで実装することができ、やりたかったことの大半はできたといえます。
このように、段階的に開発をするというのはアジャイル開発を勉強していた時に知ったもので、とても役に立ちました。
3upに関しては、魔剤を判定するモデルをつくるところまではできていたのですが、APIを叩いてmonaca側とつなげるといったところでつまずき実装には至りませんでした。以下、画像から魔剤を判定している様子です。

開発スケジュール
メンバー同士の予定がなかなか合わなかったこともあり、我々の当初の予定は以下の通りでした。
月、火 開発 水、木 休み 金 開発&発表練習 土 発表
実際はこうなりました。
月、火、水、木、開発 金 発表練習 土 発表
しんどかった。。。。
徹夜して開発した日もありました(メンバーの中には、サッカーサークルの合宿にPCを持って行って徹夜をした勇者もいた)。
どうやったら余裕もった開発スケジュールを立てることができるのだろうか・・・
永遠の謎です。
役割分担
明確に決めたわけではなかったのですが、自然とそれぞれの役割に分かれました。
- DB
- Google Maps API
- 画像
- UI
- 画像認識
発表準備
我々が狙っていた賞は、HappyHacking賞です。会場投票で1位を得るためには、とにかくウケる必要があります。 また、発表は180秒。短い間で、どれだけインパクトを残せるかが焦点になってきます。
プロ研Slackの HACK U チャンネルが本物の闇抱えてて草生えない pic.twitter.com/nxp0HNLrCR
— tanacchi (@q111026d) 2019年8月23日
そこで、このように発狂している様子をスライドに盛り込みました。
このほかにも魔剤を見つけた喜びや、魔剤がなかった時の落ち込み、魔剤摂取して発狂している様子など、多くの画像があります。
これらの画像によって、どのような場面を想定してこのアプリを開発したか、伝えることに成功したと思います。 自分をフリー素材化する。とてもいいのでみなさんもぜひやってみましょう。
スライドの配色にもこだわりました。
いつもはシンプルなスライドを作ることが多いのですが、今回はバリッバリに警告色をつかい毒々しさをアピールしました。
とっても楽しかったです。
▂▅▇█▓▒░(’ω’)░▒▓█▇▅▂うわあああああああああああああああ
また、このアプリのデータはユーザーが投稿する必要があるため、当日早めに集まり会場周辺のデータ集めを行いスライドに反映させました。 UGC : ユーザーの手によって制作・生成されたコンテンツの総称
データ集めして感じたことは、コカ・コーラエナジーの販売箇所が多いということです。大概のコーラ社の自販機においてあります。やはり、自販機を持っているのは強いですね。実際どのくらい売れているか気になりました。
発表を振り返って
ありがたいことに、大成功でした。 全チームの中で一番ウケていた自信があります。
発表が開始すると同時に「プシュッ」と魔剤をあけ、発表している横でひたすら飲むというパフォーマンスがあったおかげかもしれません(たぶん史上初)。
40秒を残して、無事に発表を終えることができました。
デモを振り返って
会場にいた我々以外の魔剤中毒者の方々に、「早く公開してください!」と言われたのはめちゃくちゃうれしかったです。
また、興味を持ってブースに来てくださった方の9割以上の質問が、
「どうやってデータを集めたの?」
といったものでした。
発表では魔剤情報を調べるという一番大きな部分に絞っており、魔剤スポットの追加については触れていなかったためだと思います。
「足で稼いだ」と答えると皆さんとても驚かれました。
このデータをどうやって集めるかというのが、今後の課題になると思います。
今後
自販機の情報は公開されていないのが現状なので、ユーザー投稿型にするしかないかな~と今のところは考えています。 その際、魔剤スポットとして登録する部分をいかに効率化できるかが焦点であるとも考えています。その手段の一つが、画像認識による魔剤の特定であると考えていますが、ほかにもいい案がないか引き続き検討していきます。
そして!!
このたび、「エナしるべ」をAndroidアプリとして公開します!!!
現在審査中です。
審査が終わり次第告知させていただきます。
2019年8月31日追記
無事、リリースされました!
以下、リンクよりダウンロードお願いします。
(一部機能を制限しています)
以上、Hack U 2019 FUKUOKA参加レポートでした。
賞をとれなかったのは残念ですが、今回のハッカソンもとても楽しかったです。
実は、Hack Uへの参加は今回で2回目でした。会場に行くと、社員さんに「お、去年もいたね!去年のアプリ、好きだったよ!」との声をかけていただきとてもうれしかったです。下に、前回の様子を載せておきます。
Hack U 2018 FUKUOKAにて
遅刻するかどうかを判定してくれるアプリ「遅刻チェッカー」を開発し、HappyHacking賞(会場投票賞)を受賞。
昨年度の様子(36分6秒~)
Hack U 2018 FUKUOKA プレゼンテーション・作品展示会・表彰式 - YouTube